Here's a scenario we see constantly: an organization invests significantly in a SIEM platform, ingests logs from dozens of sources, and within months, the security team is drowning in thousands of daily alerts. Meanwhile, real attacks slip through unnoticed because the signal is lost in the noise.
This is the detection engineering problem, and solving it requires moving beyond "collect logs and create rules" to a systematic approach to threat detection.
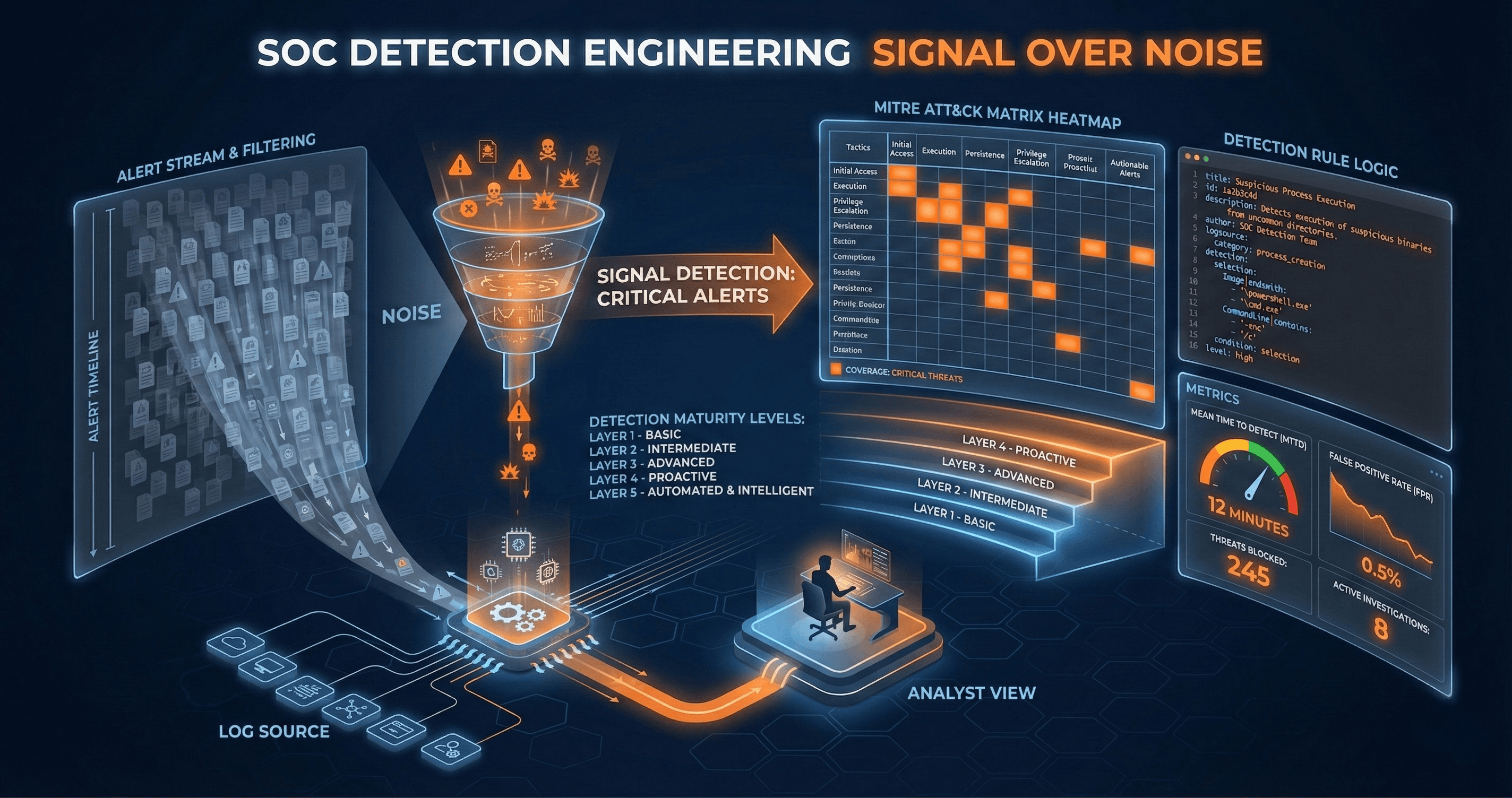
The Detection Maturity Model
Organizations typically progress through distinct stages of detection capability:
Level 0: Reactive
- Detections created only after incidents
- Heavy reliance on vendor-provided rules
- No documentation of detection logic
- High false positive rates accepted as normal
Level 1: Basic
- Some proactive detection development
- Detections aligned to known threats
- Basic documentation exists
- False positive tuning happens, but inconsistently
Level 2: Systematic
- Threat intelligence drives detection priorities
- Detections mapped to MITRE ATT&CK
- Detection-as-code practices adopted
- Regular tuning and validation cycles
Level 3: Advanced
- Hypothesis-driven detection development
- Automated detection testing and validation
- Behavioral analytics complement signature-based detection
- Continuous coverage measurement against threat landscape
Most organizations we assess are somewhere between Level 0 and Level 1. Moving to Level 2 and beyond requires deliberate investment in people, processes, and technology.
MITRE ATT&CK as a Detection Framework
The MITRE ATT&CK framework provides the common language and structure that detection engineering requires. Rather than thinking about detections as isolated rules, ATT&CK helps you think about adversary behaviors and techniques.
Using ATT&CK Effectively
Map your current coverage: Start by mapping your existing detections to ATT&CK techniques. This immediately reveals gaps. Most organizations discover they have reasonable coverage for a handful of techniques (typically initial access and execution) while having almost nothing for persistence, defense evasion, or lateral movement.
Prioritize based on threat intelligence: Not all techniques are equally relevant to your organization. A financial services firm faces different threats than a healthcare provider. Use threat intelligence to identify which techniques are actually being used against organizations like yours.
Build detection hypotheses: For each priority technique, develop hypotheses about what observable evidence would indicate that technique is being used. This is where detection engineering becomes systematic rather than ad hoc.
A detection hypothesis is a testable statement about what you'd expect to see if a specific attack technique was occurring. For example: "If an attacker is using Pass-the-Hash, we would expect to see NTLM authentication events with event ID 4624 type 9 from workstations that aren't typical for the source-destination pair."
Building Effective Detection Rules
Good detection rules share common characteristics that distinguish them from the default rules that generate alert fatigue.
Anatomy of a Strong Detection
1. Clear scope and purpose
Every detection should document:
- What technique or behavior it detects
- What data sources it requires
- What limitations it has
- Under what conditions it might generate false positives
2. Appropriate specificity
Generic detections generate noise. Effective detections are specific enough to identify malicious behavior while filtering normal activity. This usually means including multiple conditions.
Bad example:
alert any network where destination_port = 445
This will generate thousands of alerts for normal SMB traffic.
Better example:
alert where
destination_port = 445 AND
source.asset_type = "workstation" AND
destination.asset_type = "workstation" AND
NOT (source.ip IN corporate_subnets) AND
bytes_out > 1000000
This focuses on the specific behavior we care about: large file transfers between workstations from unexpected sources.
3. Contextual enrichment
Raw alerts are hard to investigate. Effective detections include or reference:
- Asset ownership and criticality
- User and account context
- Historical baseline information
- Relevant threat intelligence
Testing Your Detections
A detection that has never been tested against actual attack behavior is hope, not security. Every detection should be validated through:
Atomic tests: Use tools like Atomic Red Team to simulate specific techniques and verify your detection triggers appropriately.
Purple team exercises: Collaborate with offensive security to test detections against realistic attack chains, not just isolated techniques.
Retroactive analysis: When incidents occur (internally or reported externally), analyze whether your detections would have caught the activity. This reveals gaps in both detection logic and data collection.
If you're not regularly testing your detections, you're operating on assumptions. We've seen organizations with hundreds of "active" detections where fewer than 20% would actually fire on the behavior they claim to detect.
The Tuning Imperative
Detection engineering doesn't end when a rule is deployed. Continuous tuning is where the real work happens.
Establishing a Tuning Process
Track false positive rates: Every detection should have a documented false positive rate that's reviewed monthly. Rates above 50% indicate a rule that needs significant refinement or retirement.
Create feedback loops: Analysts investigating alerts should have a simple way to flag false positives and provide context. This feedback must flow back to detection engineers.
Conduct regular reviews: Schedule monthly reviews of high-volume alerts. Ask: Is this detection providing value proportional to the investigation time it consumes?
When to Retire Detections
Not every detection is worth maintaining. Consider retirement when:
- False positive rates remain high despite tuning attempts
- The underlying technique has been mitigated by other controls
- The data quality is too poor to support accurate detection
- Investigation of alerts consistently provides no actionable intelligence
Measuring Detection Effectiveness
You can't improve what you don't measure. Key metrics for detection programs include:
Coverage Metrics
| Metric | How to Measure | Target |
|---|---|---|
| ATT&CK technique coverage | Techniques with at least one tested detection / Total prioritized techniques | Over 60% of priority techniques |
| Data source coverage | Required data sources available / Total needed for priority detections | Over 80% |
| Detection test pass rate | Detections that fire on simulated attack / Total detections tested | Over 90% |
Operational Metrics
| Metric | How to Measure | Target |
|---|---|---|
| False positive rate | False positive alerts / Total alerts | Under 30% |
| Mean time to detect (MTTD) | Time from attack execution to alert | Varies by technique |
| Alert-to-investigation ratio | Alerts escalated for investigation / Total alerts | Over 10% |
Outcome Metrics
| Metric | How to Measure | Target |
|---|---|---|
| Incidents detected by SIEM | Incidents first identified through detection / Total incidents | Over 70% |
| Dwell time reduction | Average time attackers present before detection (year over year) | Declining trend |
Building a Detection Engineering Practice
Organizations ready to move beyond ad hoc detection development should consider:
Dedicated Roles
Detection engineering is a specialized skill that combines:
- Deep technical knowledge of attack techniques
- Strong analytical and data science capabilities
- Understanding of your specific environment and normal behavior
- Software development practices for detection-as-code
This combination is rare. Invest in developing these skills within your team or work with specialists who bring this expertise.
Infrastructure Requirements
Effective detection engineering requires:
- Test environment: A place to safely simulate attacks and validate detections without risking production systems
- Detection management system: Version control, testing pipelines, and deployment automation for detection rules
- Analytics platform: Capability to query historical data for hypothesis validation and detection development
Process Integration
Detection engineering should integrate with:
- Threat intelligence: New intelligence should trigger detection hypothesis development
- Incident response: Post-incident reviews should identify detection gaps
- Vulnerability management: New vulnerabilities should prompt detection development for exploitation attempts
- Red team operations: Offensive exercises should validate detection coverage
Getting Started
If you're beginning a detection engineering journey, start here:
Week 1-2: Inventory existing detections and map to ATT&CK. Calculate current coverage percentages.
Week 3-4: Identify your organization's priority techniques based on threat intelligence and business risk.
Month 2: Select five priority techniques with poor or no coverage. Develop detection hypotheses for each.
Month 3: Build, test, and deploy detections for priority techniques. Establish baseline metrics.
Ongoing: Institute monthly tuning cycles and quarterly coverage reviews. Expand coverage systematically.
The Real Goal
The goal of detection engineering isn't to have the most alerts or the most rules. It's to reliably identify attacks that matter to your organization before they achieve their objectives.
This requires moving beyond vendor defaults, investing in systematic processes, and continuously validating that your detections work. The organizations that do this successfully transform their security operations from reactive firefighting to proactive threat management.
Related Service
Learn more about how we can help with Security Engineering.
Explore Security Engineering Services →