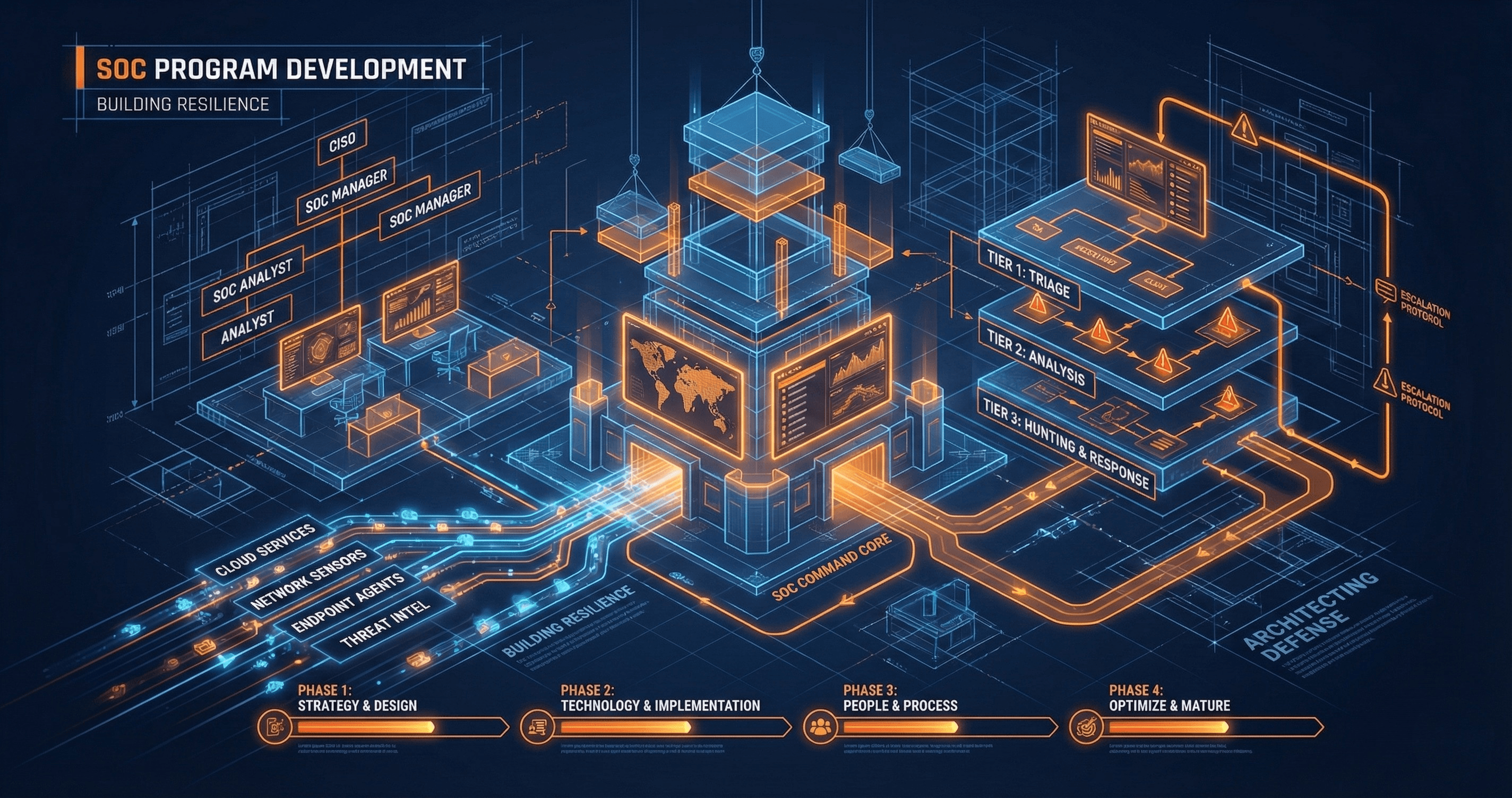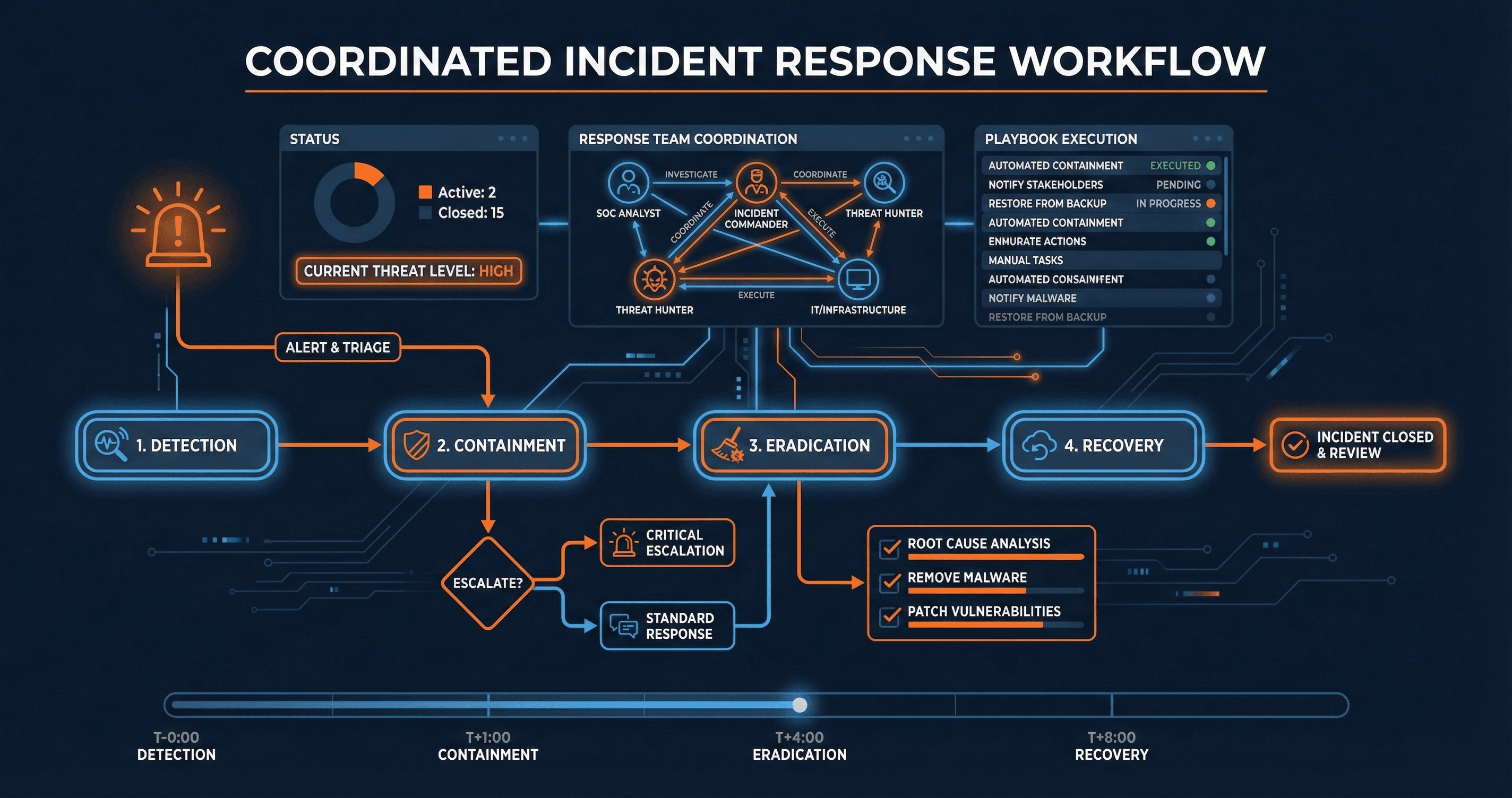
It's 2 AM. Your phone buzzes with an alert: suspected ransomware activity detected. Your heart rate spikes. What happens next determines whether this becomes a contained incident or a catastrophic breach.
Most organizations have an incident response plan somewhere, usually a PDF that was written years ago and reviewed never. When the pressure hits, that document sits unused while responders scramble to figure out what to do.
Effective incident response requires more than a plan. It requires playbooks: specific, actionable procedures for common incident types that your team can execute under stress.
Why Most IR Plans Fail
We've reviewed hundreds of incident response plans. Most share common failures:
Too High-Level
Generic guidance like "contain the threat" or "preserve evidence" isn't helpful when you're staring at an active intrusion. Responders need specific steps: which systems to isolate, which commands to run, whom to notify.
Never Practiced
A plan that hasn't been tested through tabletop exercises or simulations is hope, not preparation. When the pressure hits, responders won't remember procedures they've never practiced.
Organizationally Ignorant
Plans that don't account for your specific environment (your network architecture, your critical systems, your escalation paths) are generic templates that provide little actual guidance.
Outdated
The plan written when you had 50 employees and a single office doesn't work when you have 500 employees across multiple cloud platforms. Plans require regular updates as environments change.
If you can't point to specific playbooks that your team has practiced within the past 6 months, you don't have an effective incident response capability. You have documentation that will be ignored during a crisis.
The Playbook Hierarchy
Effective incident response documentation exists at multiple levels, each serving a different purpose.
Strategic: Incident Response Policy
Purpose: Establish authority, define roles, set expectations.
Contains:
- Incident classification definitions
- Authority to take containment actions
- Notification and escalation requirements
- External communication guidelines
- Legal and regulatory obligations
Updated: Annually or when organizational structure changes.
Tactical: Response Procedures
Purpose: Guide overall response for incident categories.
Contains:
- General approach for incident types (malware, data breach, insider threat)
- Decision frameworks for escalation
- Team coordination procedures
- Documentation requirements
- Transition between response phases
Updated: Semi-annually or when major process changes occur.
Technical: Response Playbooks
Purpose: Provide step-by-step actions for specific scenarios.
Contains:
- Exact commands and procedures
- Tool-specific instructions
- Decision trees for common situations
- Specific contacts and escalation paths
- Evidence collection procedures
Updated: Quarterly and whenever tools or environments change.
Essential Playbooks Every Organization Needs
At minimum, your organization should have tested playbooks for these scenarios:
1. Malware/Ransomware
The most common serious incident. Your playbook should address:
Initial Detection:
- Verification steps (is this a real incident or false positive?)
- Initial scoping (how many systems affected?)
- Isolation decision criteria
Containment:
- Network isolation procedures
- System isolation options
- Credentials to disable
- Backup verification steps
Investigation:
- Evidence collection procedures
- Malware analysis workflow
- Lateral movement investigation
- Initial access determination
Recovery:
- System rebuild or restore procedures
- Validation before reconnection
- Monitoring requirements post-recovery
2. Business Email Compromise
BEC attacks often don't trigger technical alerts. Playbook should cover:
Detection:
- Financial department notification procedures
- Email account compromise indicators
- Third-party notification handling
Containment:
- Account lockout procedures
- Mail rule review process
- Forwarding removal steps
Investigation:
- Email log analysis
- Financial transaction review
- Contact verification procedures
Recovery:
- Account restoration process
- Financial recall procedures
- Customer/partner notification
3. Data Breach/Exfiltration
When sensitive data may have been accessed or stolen:
Initial Assessment:
- Data classification review
- Scope determination procedures
- Regulatory notification timeline review
Investigation:
- Access log analysis
- DLP alert review
- Network traffic analysis for exfiltration
Containment:
- Access revocation procedures
- Additional monitoring implementation
- System isolation if ongoing
Notification:
- Legal review triggers
- Regulatory notification procedures
- Customer notification templates
4. Insider Threat
Different from external attacks because it involves trusted users:
Detection:
- Behavioral indicators
- DLP alert handling
- HR notification triggers
Investigation:
- Covert vs. overt investigation decision
- Legal/HR coordination
- Evidence preservation for potential litigation
Response:
- Access modification procedures
- Monitoring implementation
- Termination coordination (if applicable)
5. Denial of Service
When availability is impacted:
Verification:
- Confirm attack vs. technical failure
- Identify attack type and vector
Mitigation:
- ISP notification procedures
- CDN/WAF configuration changes
- Traffic scrubbing activation
Communication:
- Internal stakeholder notification
- Customer communication templates
- Status page update procedures
Building Playbooks That Work Under Stress
Playbooks that get followed in a crisis share certain characteristics:
Clarity Over Comprehensiveness
Under stress, responders need clear direction, not extensive options. Each step should be unambiguous:
Bad: "Isolate affected systems as appropriate based on business impact assessment."
Good: "Isolate the affected system by disabling the network interface. If the system is business-critical, escalate to the IR Lead before isolation. Command: netsh interface set interface 'Ethernet' disable"
Decision Trees, Not Judgement Calls
When possible, provide clear decision criteria rather than requiring judgement:
Is the affected system:
├── Domain controller → Escalate to IR Lead immediately
├── Production database → Notify DBA on-call, assess before isolation
├── Standard workstation → Isolate immediately, notify user's manager
└── Development system → Isolate immediately, no notification required
Contact Information That's Current
Nothing derails incident response faster than outdated contact information. Playbooks should include:
- Primary and backup contacts for each role
- After-hours contact procedures
- External contacts (legal, PR, vendors)
- Last verified date for all contacts
Tool-Specific Instructions
Generic procedures don't help when every environment is different. Include:
- Exact console paths for your tools
- Specific queries for your SIEM
- Commands formatted for your systems
- Screenshots for complex procedures
Test every command and procedure in your playbooks. We've seen playbooks with syntax errors, deprecated commands, and procedures that simply don't work in the actual environment. If a responder has to troubleshoot the playbook during an incident, you've already lost critical time.
Integrating Playbooks with SOAR
Security Orchestration, Automation, and Response (SOAR) platforms can transform playbooks from documents into automated workflows. Key integration points:
Automated Initial Steps
Many early response steps can be automated:
- Alert enrichment (who owns this system? What's its criticality?)
- Initial data gathering (recent logins, process lists, network connections)
- Notification of relevant parties
- Ticket creation and documentation
Human Decision Points
SOAR workflows should pause for human decisions at critical junctures:
- Containment actions that affect production
- Escalation decisions
- External notifications
- Recovery authorization
Documentation Generation
Automated documentation of:
- Actions taken and timestamps
- Evidence collected
- Decisions made and by whom
- Deviations from standard procedure
Testing and Exercising
Playbooks only work if your team has practiced them. Implement a regular exercise program:
Tabletop Exercises (Monthly)
Walk through scenarios verbally without touching systems:
- Takes 1-2 hours
- Identifies gaps in procedures and communication
- Low effort to organize
- Can include non-technical stakeholders
Technical Drills (Quarterly)
Execute playbook steps in a test environment:
- Validates technical procedures actually work
- Identifies tool proficiency gaps
- Takes half day to full day
- Requires coordination with IT operations
Full Simulations (Annually)
Realistic exercises with surprise timing:
- Tests entire response capability
- Involves all relevant stakeholders
- Identifies organizational/communication issues
- Requires significant planning and resources
Post-Exercise Improvement
Every exercise should result in:
- Documented lessons learned
- Specific playbook updates
- Identified training needs
- Timeline for improvements
Measuring Response Capability
Track metrics that indicate actual readiness:
| Metric | Target | Measurement |
|---|---|---|
| Time to contain | Under 4 hours for critical incidents | Average across incidents |
| Playbook coverage | Over 80% of incidents match a playbook | Incidents requiring ad hoc response |
| Playbook accuracy | Over 90% of steps executable as written | Post-exercise validation |
| Contact accuracy | 100% reachable within 15 minutes | Exercise results |
| Exercise completion | 12 tabletops, 4 drills per year | Calendar tracking |
Getting Started
If you're building incident response capability from scratch:
Week 1: Define your incident classification scheme and escalation matrix.
Week 2-3: Build your first playbook. Ransomware is typically highest priority.
Week 4: Conduct a tabletop exercise using the new playbook.
Month 2: Build playbooks for BEC and data breach scenarios.
Month 3: Integrate playbooks with your SOAR platform or ticketing system.
Ongoing: Monthly tabletops, quarterly drills, continuous playbook refinement.
The Bottom Line
When an incident occurs, your responders don't have time to read a 50-page document or make up procedures on the fly. They need specific, tested playbooks that tell them exactly what to do.
Building these playbooks takes effort. Maintaining them takes discipline. But the alternative, chaos during your worst moments, is far more expensive.
Related Service
Learn more about how we can help with Security Operations.
Explore Security Operations Services →